

Recently we’ve been thinking a lot about why companies are leaving the cloud and going back to owning or renting their own hardware. It might sound like a step backwards, but the business sense often stacks up.
We’ve already written about what’s attracting people away from the cloud - namely, grunty servers that don’t cost a lot and which offer incredible performance. Today you can pay a low, fixed price to access entire Dedicated Servers with CPUs and storage that would have been unimaginable a few years ago. Or you could choose a High Performance Virtual Server, built on technology that has swept away older VPS benchmarks.
There are also push factors at play. Things about “the cloud” that businesses don’t like. Cost, mostly. For leaders like David Heinemeier Hansson, co-founder of 37signals, this included “our disappointment over not being able to operate the [cloud] system with materially less staff" than running their own hardware. If cloud services don’t lower your DevOps costs, then they need to lower your infrastructure costs instead. After all, on-demand computing’s big promise is efficiency, right?
We didn’t have to look far to find someone to ask about this. Someone who has wrestled with AWS bills and has the scars to prove it.
Ben runs our Product & Automation team here at SiteHost. The developers in his team have been working on a product that runs on AWS for a few years now, and it’s fair to say that they have learned a lot. Ben has also helped SiteHost customers make much better use of the money that they spend with AWS.(That’s right, even though we own and run our own data centre we help people optimise their hosting wherever it is.)

We talked with Ben to understand why cloud services don’t let you run a leaner team, and why cost management can get so hard.
How AWS cost management creeps up on you
Given Ben’s experience helping SiteHost customers manage their AWS bills, he knew that costs were going to be difficult to manage on our internal project. But because things started small, they were quiet to begin with.
“It probably took a year or so for things to really bubble up. At first we were creating something like one Lambda function or EFS volume a day. Now that we’re closer to having our infrastructure finished, we’ve scaled up, and more people are actively working on it. So what was one a day has become hundreds a day,” Ben says.
The way the project grew hid some issues for a time. “Pieces of infrastructure were progressing fast in AWS while we were making more changes in shorter periods of time. We just kind of got used to the gradual increase in the billing climate,” Ben says.
The bill went up 8% this month, which seems reasonable, but then you look back and see that it’s gone up 8%, 10%, 20% every month for the last year. We're spending three times what we were, but we’re not getting three times as much value.
There were a lot of reasons for this - “death by a thousand cuts”, as Ben says. It took a lot of effort to understand which cuts were deepest, which were easiest to reverse, and which are now cheaper to live with rather than fix.
Related article - Dave Sparks of Sparks Interactive
"AWS did support growth, but I think within the first six months, the monthly cost tripled without our workload necessarily tripling. We were working so much harder, doing so much more. So why was the bottom line not joining us on that journey of joy?"
Learning to avoid AWS cost pits
Learning by doing is part of the job for any developer, but AWS puts a literal price on a lot of lessons.
At first, like any developer learning their way around AWS, our team didn’t always appreciate the costs of their work. One of the first things to understand was what services we had in play.
“There was more infrastructure across more accounts, and less scrutiny being paid to the costs, than we thought,” Ben says.

“Let’s say that a dev environment uses more disk space than it should, because someone forgets to delete something. That costs an extra 20 cents a day. Then say you have 10 developers with their own environments. And then maybe you do something like attach an EFS volume for every Lambda you create. None of this is a problem so long as you're cleaning things up as you go, which is harder than you would think. And if you don’t, it’s going to take time for you to notice the build-up.”
Issues aren’t always easy to spot in low-traffic development environments. This can make it tricky to even know what, exactly, ought to be cleaned up. By the time you’re in production, where higher traffic volumes reveal areas of bloat, it can be too late.
As a developer your focus is generally on solving the problem at hand and getting the thing working first. Performance is a consideration, security is always a consideration, and now billing is yet another one. You need to ask how expensive this is going to be, how we’ll track those costs, and how to ensure that shipping this to production won't increase costs.
In short, there is a new set of overheads to shipping code. More to think about and more to pay.
“That wasn’t the case when you just bought a server or virtual machine, because if your code was a bit shoddy you still paid a fixed cost. You could optimise the amount of disk it wrote or CPU cycles it used later, and that is still the attitude that developers traditionally take,” Ben says.
“But now you realise that ‘optimise later’ actually needs to happen quite quickly, because costs balloon out of control. For most developers this sort of thing won’t be a priority, at least not until they’ve learned hard lessons. For companies it means that you need to do education about cost controls, or you need to have protections in place.”
Guessing what code will cost before it runs
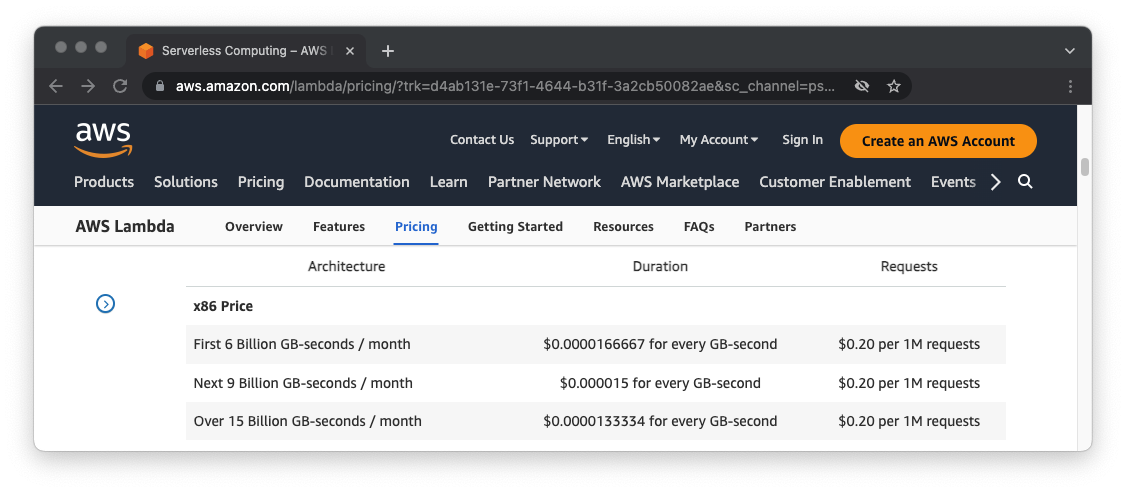
You might wonder why Ben and his team don’t simply look up costs in advance. After all, AWS publishes incredibly detailed pricing tables. Almost too detailed, as it turns out.

“Costs are split up into such small chunks - like tenths of cents, or cost per hour or per gig - that it's almost impossible to get accurate measures until you've built something. If you’re building a service, do you know how much data it's going to write and send across the network every hour? Probably not until you start using it,” Ben says.
From a coding point of view, information about what things will cost is abstracted away
Besides, even with a deep understanding of the services that you’re working with, there will always be unknowns.
“EC2s are just VMs. You can work out the cost for an EC2 instance per month apart from data transfer costs or maybe disk space,” Ben says.
It gets harder with other services.
“The more complex pieces involve more usage-based billing. You cannot work out your Lambda costs for a month unless you know exactly how many requests you’ll be sending, and how long they're all going to take. Even then, one line of code can change that.
“If you have a Lambda function that takes 100 milliseconds to process and then you ship a line of code that means it now takes 200 milliseconds to process, you've doubled your Lambda costs. But is the developer going to notice a 100ms change?”
“You could argue in some ways that it's good for people to be more aware of the resources they're using. But it definitely slows things down and makes decisions harder.”
Trying to see what code costs as it runs
If you can’t predict costs in advance, you need to track them as they are incurred.
So, how hard is that? Very.
Problem number one is that AWS billing is famously opaque, with infrequent updates that can take 24 hours to arrive. There is no way to directly see what anything costs in anywhere near real-time.
Then there’s the extra cost that small mistakes can carry.
The bug that taught us the most
Expensive problems can stay hidden for quite a while. Like when a team member shipped code that contained an infinite loop which ran, undetected, for days.
“It took us four days, including a weekend, to notice, and now last month’s entire AWS bill is 30-35% higher than usual from just that one bug,” Ben says.
This problem could only happen because the team was using scalable cloud services.
“If you have a traditional server and you ship code with an infinite loop in it, the server will crash and that’s your alarm. One of those great things about scalability is that you don’t crash like that. It’s also one of the downsides of scalability, that your infinite loop just keeps going in the background until you get a notification about the size of your bill,” Ben says.
Incredibly, in-built AWS tools didn’t see the infinite loop as a problem. Like most things in AWS, billing alerts require some trial and error - and they don’t always work like you need them to.
For a start, alerts rely on billing data that arrives up to 24 hours after the fact. Then they run daily, so they’re a lagging indicator at best. At worst, they never indicate anything.

Ben says, “One mistake was that we relied on AWS's own budget predictions to set an alert threshold. But it’s based on six months of data and it doesn't do any anomaly detection.”
A bad bug like the one we shipped didn’t trip any alarms. Instead, it caused the machine to bump up the next month’s alert threshold by 30% across the board.
Ironically, Amazon has introduced infinite loop detection now, but it won’t work with how we use Lambda. It would take too much effort to re-engineer things to fit, so for us this problem literally wasn't worth solving the AWS way. Instead our team needs to track costs and trace issues themselves, which is not simple.
“To have effective budget alerts you need telemetry data,” Ben says.
“You need to intimately understand every piece of your infrastructure and its usage patterns. Then you need to manually set good alerts with those patterns in mind. And you need to have anomaly detection, which in an ideal scenario would have picked up the infinite loop.”
Service-by-service, different issues cause AWS cost blowouts
Ben’s talking from experience about understanding every single part of your infrastructure and its usage patterns. Lambda, KMS and EBS, for example, are three different services that need three different approaches to cost control.
He says,“Lambda functions usually live anywhere up to 15 minutes, and then they can disappear off the face of the Earth. You could have a bug that costs a bunch of money and never happens again, or only every few weeks. That’s not easy to trace. There are ways of finding out that it’s, say, compute in one particular region. But that doesn’t tell you what code was running or whether it was doing what we expected. You need to go through these things and properly understand them.”
While Lambda functions can only really be analysed after the fact, KMS is a different story.
“KMS is the service to store and retrieve secrets like encryption keys. Is it reasonable that we spent $37 one month? We know how many keys we’re storing and how many requests we made, but unless we work to review that usage we don’t know what our ‘correct’ cost is” Ben says.
“KMS costs a dollar per key out of the box. That’s a dollar per month for every environment before we’ve even started. If someone starts generating, storing and retrieving a key every time they need it, that’s another dollar every time. It’s expensive for what it is, but you’re not going to spot those extra dollars for a while.”

Best practice with KMS ought to be relatively easy to define, and then it’s a matter of whether the entire team knows, and always follows, it. EBS presents another sort of problem - a situation where standard practice was overly expensive to begin with.
Ben says, “One of our big costs were storage volumes, called EBS. We were using 30GB volumes, because that’s the space required by the default Amazon image on ECS. That was okay until we started provisioning a lot more of these volumes.
“When you're building something you're going to reach for the default image and the volume it comes with. But when we made an Amazon AMI image for ourselves, it fit into a 10GB volume”
Just by changing the image away from the default we cut our EBS bills by 66%.
This taught us that AWS isn’t incentivised to help us optimise things. The opposite, in fact - by defaulting to oversized volumes, they sell more EBS space. For us, ready-to-go images come with an EBS tax, but the build-your-own route takes time and maintenance effort. There are traps on both sides.
Ben says, “Usually, no one's going to wonder whether we could optimise an image in order to downsize our volumes. This is what I mean when I say that developers are learning hard lessons, and they’re not currently geared to think this way. They’re used to infrastructure that’s a lot harder to do damage on, from a cost perspective.”
Our developers also learned a lesson about tidying up after themselves.
“Our EBS volumes weren’t always cleaned up correctly, due to an issue at our end. They were left sitting there and their cost grew. That’s not going to stand out in a bill of a few thousand dollars at first, but it represented a 500% increase for that service,” Ben says.

“These things can happen silently in the background, and spotting that change when it's a few dollars in this service, a few dollars in that service, is difficult and time consuming. You have to have the right tooling in place.”
Recommendations from an AWS user who’s been there, paid that
Ben has learned lessons from major bugs like an expensive infinite loop, and from many less damaging experiences like suboptimal EBS volumes. So he has a clear idea of the tooling that’s important for cost controls.
“If we could rewrite everything from scratch right now, billing would be at the forefront. We were always trying to build a cost efficient product, but that’s very different to knowing what protections you need and how to deliver them. We didn't know that we were going to need infinite loop protection until we created one at scale,” Ben says.
Where we tried to optimise costs or be efficient, it either wasn't the right place or wasn't enough.
Telemetry data and anomaly detection
“Now we know that you need some form of anomaly detection that works on a daily basis at least, but ideally hourly - quicker than AWS’s billing data. If a developer ships a bug at 5pm and we notice it at 9am tomorrow, that could be thousands of dollars.”
“Say you’re running an API out of Lambda. Can you detect how long things are taking there? Do you have telemetry data, do you know the average time an API request takes? Do you have a way of knowing if it breaks and takes five minutes?” Ben asks, rapid-fire.
“All the data is available if you put the time and effort into building out the information, but access to some of it is charged for as well. You can do this with third party tools in some cases, but a lot of businesses won't know what they need until they need it.”
Close scrutiny of every bill
Ben also recommends a routine backward-looking review.
I would say that realistically, you need someone to carefully review your bill every month - spotting patterns, causes of consistent growth and outliers. That person is looking for anomalies, identifying expensive services, and cutting those costs.
This isn’t a job for an accountant. It’s important that the person doing this has sufficient technical knowledge.
“Often when you're investigating a bill you're looking in a haystack for a very expensive needle. Once you’ve found it, you've got to understand what you've done wrong architecturally, and then rethink it,” Ben says.

AWS bills claim to be an open, granular breakdown of everything - fully transparent. In reality, they can raise difficult questions with no obvious answers. In fact AWS bills are so difficult to comprehend and reduce that there are entire consulting businesses that do only that.
A quick tour of a complicated bill
Ben’s ideal bill reviewer would have a fine-tooth comb and two big questions:
What, exactly, is contributing to the largest items on our bill?
What is pushing up the lines that are growing quicker than they should?
Taking a recent bill of ours as an example, he shows how that would look.
“Right now we have 34 line items on our AWS bill, one for each service. You go into one of those services, say Lambda, and it’s broken down by Region. EC2 breaks down by instances,” he says. In a few clicks he’s drilled down into hundreds of rows.
One Lambda row shows how many seconds we used in one particular region. It’s a big number.
“Now you need to know how many millions of seconds you would expect. How do I dig into that? How do I go and work out exactly what that cost is for?”
Little numbers need to be interrogated too. Another Lambda row comes in at $1.83. Ben says, “If that was 30 cents last month, we might have a problem.”
He’s attuned to the multiplier that would be at play here. From 30 cents one month to $1.83 the next, that rate would take us up to $11, then $68, and so on. The step from development to production could put a heavy foot on the same accelerator.
Before closing the AWS Cost Management tool, Ben points out another line which says that we spent a few dollars running queries against…the AWS Cost Management tool. Nothing comes free.
Big questions, big savings
By asking why things cost what they do, and what’s driving the biggest changes, you can find some serious saving opportunities.

Ben says, “Everyone will have their own sort of billing pain. Or they just won't realise that they're spending more than they should. We've spoken to businesses who say, ‘yeah, we spend this much a month and we’re fine with that’. But then we look at it and we can halve what they're spending.”
This isn’t made up.
I worked with one customer to take $4,000 a month off their bill. This is a successful New Zealand business with a smart team, doing what most people would view as a fairly stock standard, simple AWS set-up for running a large scale site. They thought it seemed expensive, but they didn't know how expensive.
Asked where those savings came from, Ben says, “We cut that $4,000 without any noticeable impact on performance or scalability. It was just over-provisioned, under-utilised, not well-monitored, lots of little things.”
We are far from the only company to have learned the hard way about the management overhead that comes with AWS infrastructure. However new code performs in development, there will be unknowns before it hits production. It’s impossible to predict what code will cost to run. Tests take time when bills take 24 hours to catch up. And there can be big penalties for anything you learn too late.
Pulling the plug
The project that Ben manages is AWS-native for a reason, so for us cost optimisation is a necessary part of the job. But it’s a never-ending battle, which leads a lot of other businesses to a major strategic junction: Why use cloud services at all?
Our interview with Dave Sparks, of Sparks Interactive, for instance, heard why they left AWS for a Private Cloud running on dedicated hardware in our Auckland data centre. It’s saved them money, simplified their operations, and took a source of stress off Dave's shoulders. We included that story, along with Ben's insights in this article, when we asked NotebookLM to make quick work of the long Cloud Exit story in October 2024.
Especially if you’re running stable workloads, dedicated hardware can be cheaper and easier to manage. Fixed costs can be a welcome relief, too.
With our experience in AWS and in running our own hardware, we’re well-placed to help you work out whether optimising cloud services or migrating to bare metal would be the right call. Get in touch for a balanced, realistic conversation.