

Most of the internet’s traffic comes from bots, and most of those bots are ‘bad bots’.
In the first part of our series on bot protection we ran you through the escalating and ever-evolving bad bot situation. Our efforts to analyse, identify and mitigate bad bot traffic have been a big change for us.
We’ve got our bot filtering system to a point where a rotating up-to-date list of 30,000 to 40,000 bad bot IP addresses are mitigated at all times. Here’s a rundown of the work we do to know which IPs to block.
Knowing where it's coming from
Every time a visitor or bot enters a URL, clicks a link, or views an image from any website hosted by our servers, a request is added to our logs. This leaves a trail of information tracked on a purpose-built dashboard, which we use to interpret around 150 million requests per day across our Cloud Containers and cPanel servers.
As soon as we see spikes in bot traffic, we use this dashboard to gather as much information as quickly as possible. We need to know exactly the source of the traffic and the patterns of its behaviour.
The first thing we want to know: where is the bot traffic coming from? This means checking its geographical location and its Autonomous System Number (ASN), a unique identifier for each network telling the internet where to deliver the data. If we suddenly see hundreds of IPs coming from the same ASN linked to an Azure server in Ireland—despite the traffic coming from different IPs—that’s a strong indicator that we’ve got bad bot traffic on our hands.
Aside from locational data, we also check to see what kind of requests the visitor is making. Some bots will make hundreds of searches per minute on a site’s search box, others will click back and forth endlessly between the same set of pages. Both are strong indicators that we’re dealing with a bad bot, but without collecting all this data we wouldn’t have a clear picture of what we’re battling.
Bots behave like bots
Once we’re suspicious of a bad bot, we take extra steps to prove that we’re dealing with bot traffic in the first place. The last thing we want to do is block human visitors.
So we developed our own Markov chain (a complex probability tree system), to measure the likelihood of traffic moving from one page to the next. If the suspected bad bot is navigating the site unpredictably, we can be confident we’re dealing with a bot.
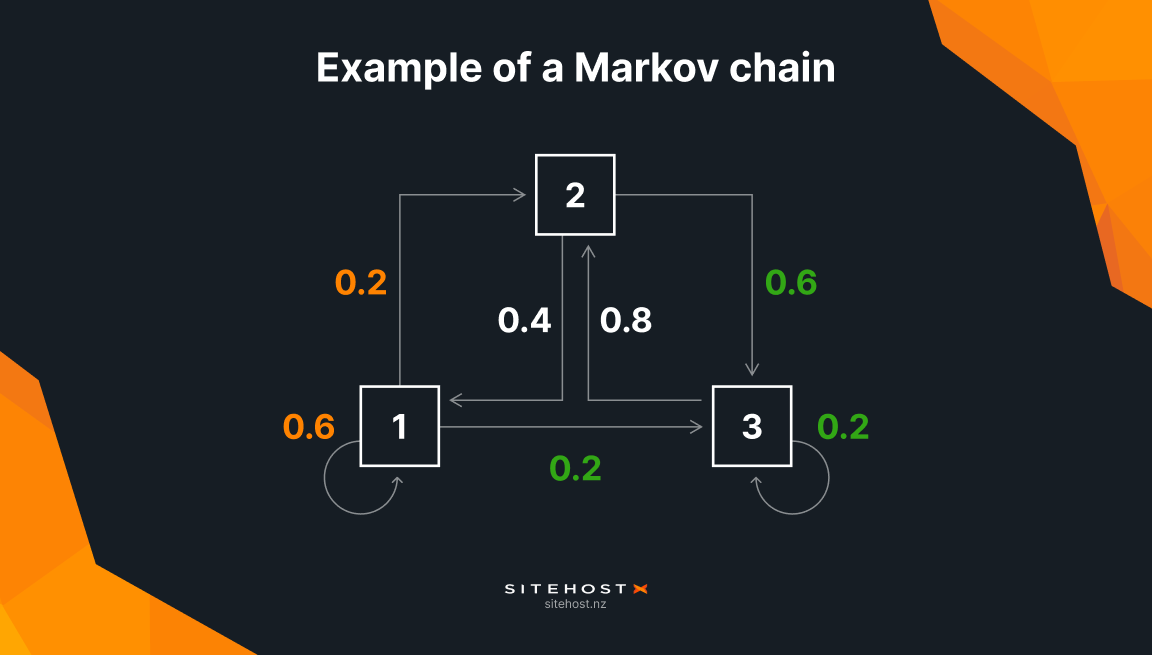
We’re looking here to see if a visitor is arriving directly on each page by brute forcing URLs, or if they visit a page and explore the website in a logical, human manner.
The chain also looks at the average duration between requests on the site (which we call mean-time variance). When a human visits a website they behave non-methodically. They’ll do something like read a page, scroll down for a couple of seconds, and perhaps leave the page open in their browser tabs for a few weeks. On the other hand, a bot will visit a page, sleep for ~100ms, make another request, and repeat the process. Because its functionality is programmed, its mean-time-variance will be very uniform. And uniformity is very unhuman.
Through lots of iteration and engineering effort, we’ve refined our system to a point where a rotating up-to-date list of 30,000-40,000 IPs are mitigated at all times.
You can put all this together. If, for example, we have a visitor jumping between pages exactly every ~50ms, navigating mostly by directly entering URLs or choosing very irregular paths, that indicates bot behaviour.
As we stand currently, this information works to confirm the traffic is coming from a bot—it doesn’t determine whether the bot is useful or malicious. That’s why we use the probability chain as a secondary measure, filtering the other data we’ve collected against it to verify bad traffic as bad bot traffic.
It's a community effort
As bots get smarter and we continue to encounter new scenarios, our flags and filters have kept changing and evolving. Our own data helps us flag bad bots that we’ve found on our own end, but we know that’s only one portion of the bad bot traffic we need to be mitigating.
So, after our own preliminary checks, we draw from a community-sourced database to widen the net of our ban list. We pull the top 30,000 bad IPs from the database every six hours and filter them against their IP range and known good bots like Google. The list is then combined with our set of flagged IPs to build out a comprehensive list of up to 40,000 IPs.
Responsible web hosting involves us reporting bad bot discoveries so action can be taken and others can be warned. We collect all the IPs we’ve flagged and report them every 6 hours to their ISPs, either by email or through API calls. This lets the ISP take any required action. We also contribute our independent bad bot findings back to the community-sourced database.
We found bad bots - what can we do about it?
Once we’ve identified traffic from a bad bot, we’ve got two ways of mitigating traffic: rate-limiting and blocking.
Rate limiting caps how often a user can repeat an action on a website within a certain timeframe. This prevents the visitor from spamming search queries or trying to log in to an account. Blocking, on the other hand, completely denies the user from accessing a site.
At any given time our system mitigates requests from all 30,000 to 40,000 IPs on our ever-evolving list, across all Cloud Container and cPanel servers.
The reality now is that bot protection is an important part of being a responsible and reliable web host. It’s worth taking stock of what your web host is doing to protect your sites from bad bot traffic.
We don’t permanently block or rate-limit IPs because cloud providers rotate IPs, which would result in blocking genuine human users at a later point. Rather, IPs are mitigated for around four hours—which from our experience is long enough to exhaust a bot’s efforts on our servers, but not so long that the IP is reused by a legitimate visitor. If a particularly persistent bot perseveres for more than four hours, we increase the mitigation time.
Over time, the steps needed to manually filter IPs have taken a lot of work. As the bad bot situation has grown, so has this manual effort. It’s not ideal for us to be manually mitigating IPs all day. It’s increasingly inefficient, and we want to operate more smartly than that. The answer is obvious, even if its implementation isn’t exactly straightforward: automation.
Blocked by one, blocked by all
We’ve set up a Cloud Container server to run scripts scraping the list of 30,000 to 40,000 IPs, updating a GitHub repository of rules with a refreshed list of flagged IPs every 10 minutes. Every Cloud Container and cPanel server we host pulls this data every 2 minutes to stay up to date with the latest set of flagged IPs to mitigate.
This method is relatively cheap on CPU, thanks to some hard work and clever engineering from our team. We live in an evolving landscape, so there will always be flare ups from time to time that need patching.
Some other companies will require you to take extra steps, like shipping all your logs to them, to try and resolve a problematic bot situation. We’d rather be more strategic and proactive for your benefit.
Effort required is increasing
Filtering gets even more difficult when you consider that not all bot traffic is bad, and not all bots are disruptive. For instance, search engine crawlers scraping your page for info is almost always positive. Bots like that usually operate in ways that don’t hog your server bandwidth. But this isn’t always the case, as some content scrapers will ignore robots.txt files, and send thousands of requests per minute.
The challenge for us is to correctly identify and mitigate the bad bots as close to 100% of the time as possible. It’s tricky, as many of our customers are doing unique things on these servers, and use bots as part of their day to day operations.
We’ve been working around those limitations and have been cautious not to be over-zealous. We do everything we can to make sure the filtering isn’t incorrectly mitigating useful bot traffic, and that human users aren’t wrongly prevented from visiting your sites. That’s why we have multiple steps along the way, filtering our detection efforts to make sure we only mitigate ‘bad bots’.
That’s where we’re at with our bad bot prevention at the moment.
The goal is to get to a point where coverage is wide enough to effectively provide community immunisation. But that’s easier said than done. Bots are getting smarter, and being designed to evade detection. Even if we get things to a perfect point one day, they'll be out of date the next.
We're not trying to build a ‘set and forget’ one-stop solution. Instead, we’re developing tools, resources and capabilities that can respond to an ever-evolving threat.
We've come a long way
A few years back we wrote about our first-hand experience mitigating thousands of IPs coming from a poorly developed Azure bot. Back in 2023, incidents like that were an anomaly worth writing about it. Now that’s just a new spike on the dashboard.
Through lots of iteration and engineering effort, we’ve refined our system to a point where a rotating up-to-date list of 30,000-40,000 IPs are mitigated at all times, and that list is downloaded by our Cloud Container and cPanel servers every 2 minutes.
The current system is a successful working solution that originated as a side project. Of course, manual mitigation is still necessary in specific cases, like for dealing with cloud bots that aggressively scape sites and generate excessive load.
As we look towards a future with more bots, both good and bad, the waters will only get muddier. There’s an ever-growing variety of AI platforms out there that we don’t even know of yet, with new tools being developed all across the world. Mitigating traffic blindly doesn’t benefit anyone, and it doesn’t make sense for us to cut off these services without due consideration.
It's now an important part of Web Hosting
Every web host in the world faces the same problem, but not every host puts the same amount of energy into dealing with it. The reality now is that bot protection is an important part of being a responsible and reliable web host. It’s worth taking stock of what your web host is doing to protect your sites from bad bot traffic.
We’ve been working so hard to make sure your servers stay unaffected that we've changed the way SiteHost operates. There’s a growing difference between hosts who do this work behind the scenes, and those that don’t. Bot protection can’t be a band-aid process, and it can’t be fixed with a one-and-done solution. That’s why we’ve been building our bot filtering efforts over time, learning what works best to protect all of our customers.
Main image created using Gemini.